Secure Computer Systems
Mandatory Access Control
11 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Mandatory Access Control
Why Mandatory Access Control
DAC has some problems which MAC tries to address.
The information flow control problem is if we share sensitive data with a person how do we prevent them from sharing that data with others. If Alice shares data with Bob, he can read the file and copy it to a new file with different permissions.
In DAC the user sets permissions. In some corporate environments the company might want to set the permissions, not the creator of the resource. This is relevant in military applications.
Labels
How can the TCB Support MAC
We need metadata/labels on our objects to support MAC. This metadata describes the nature of the data and how we can share it.
Types of information stored in metadata -
- How sensitive is the data? This helps us solve the flow control problem with enforcing confidentiality.
- What integrity level is assigned to the data?
- What is the data about?
- What kind of data can the user access (need-to-know)? This works with the metadata to determine if access is granted.
The first fundamental difference between MAC and DAC is that the MAC requires labels. These labels are a combination of a sensitivity level and a compartment. The compartment says what topics the data is related to.
How are labels used?
Suppose a user has a label L1 and an object has a label L2. We can check/compare the labels L1 and L2.
We might have label L1 = (l1, c1) where l1 is the level (how sensitive) and c1 is the compartment (what topics). The compartment is usually a set of topics (Weapons, Cthulhu, Antarctica)
Label Comparisons
Labels have a partial ordering, not a total ordering. In a total ordering things are either less than, greater than, or equal. The real numbers have a total order. Some labels cannot be compared in this way, but these relationships do exist between other labels.
- L1 > L2 (L1 dominates L2) if (L1.level L2.level) (L1.compartment L2.compartment)
- L1 < L2 (L1 is dominated by L2) if (L1.level L2.level) (L1.compartment L2.compartment)
- L1 = L2 if (L1.level = L2.level) (L1.compartment = L2.compartment)
It is possible that L2 has something in its compartment not in L1, but has a lower level. In this case we cannot compare them, they are not comparable.
Structure
Partially ordered things like MAC labels make a lattice structure.
The Least Upper Bound (LUB) of labels L1, L2, is the smallest label that dominates both L1 and L2.
The Greatest Lower Bound (GLB) of labels L1, L2, is the largest label that is dominated by both L1 and L2.
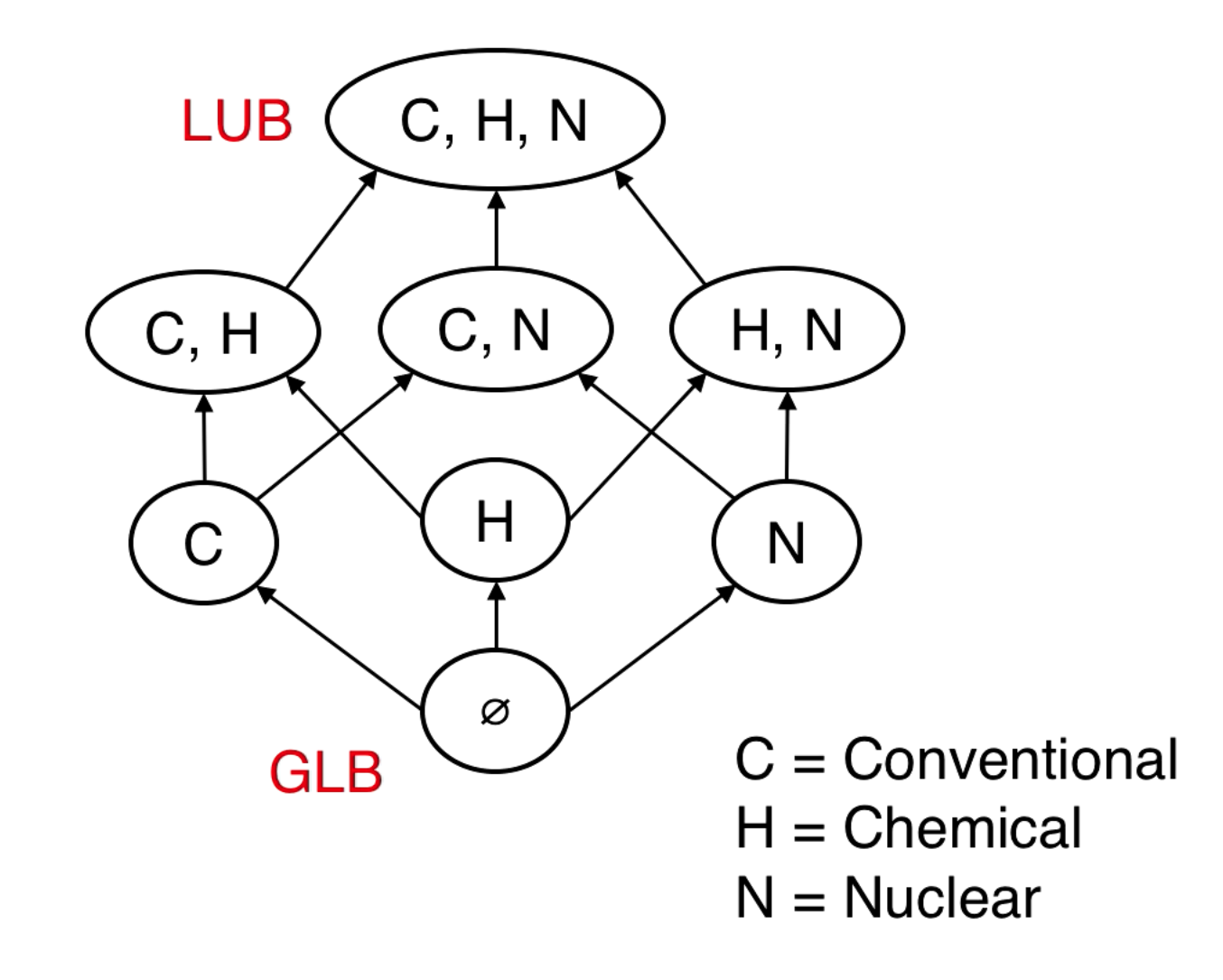
{C} and {H, N} are not comparable.
LUB() = {C, H}. also has upper bound {C, H, N} but this is not the least upper bound.
BLP Model - Read & Write rules
The BLP model is the Bell and La Padula Model, developed by DOD funded research in the 1970s. It is also called Multi-Level Security (MLS).
-
In the BLP model the label is a pair
- Label = (Sensitivity-level, Compartment or Categories)
-
The sensitivity-levels are totally ordered and the levels are -
- TS: Top secret
- S: Secret
- C: Confidential
- P: Unclassified/Public
- Compartment is some subset of all the possible categories used to describe data. These are subsets and so are partially ordered, causing the label overall to be partially ordered.
In BLP the user label is a clearance and the object label is a classification. Again, users have clearances and objects have classifications.
Access Rules
Read down rule (or simple security) - A subject S can read an object O if the label of S (their clearance) dominates the label of O (its classification). This means that your sensitivty level must be greater than or equal the sensitivity level of the object, as well as your categories must be a superset. Categories being a superset is called need to know, if you don't have access to nuclear stuff you can't read nuclear stuff, you don't need to know.
Write up rule (or * property) - A subject S can only write to an object O if O dominates S. This means a person with secret clearance can write into a top secret document (or a secret document!), but can't write to a confidential document.
The TCB checks the labels and enforces the rules.
Here is a diagram representing the access rules, an arrow going out of a subject is writing an object, an arrow going into a subject is the subject reading the object:
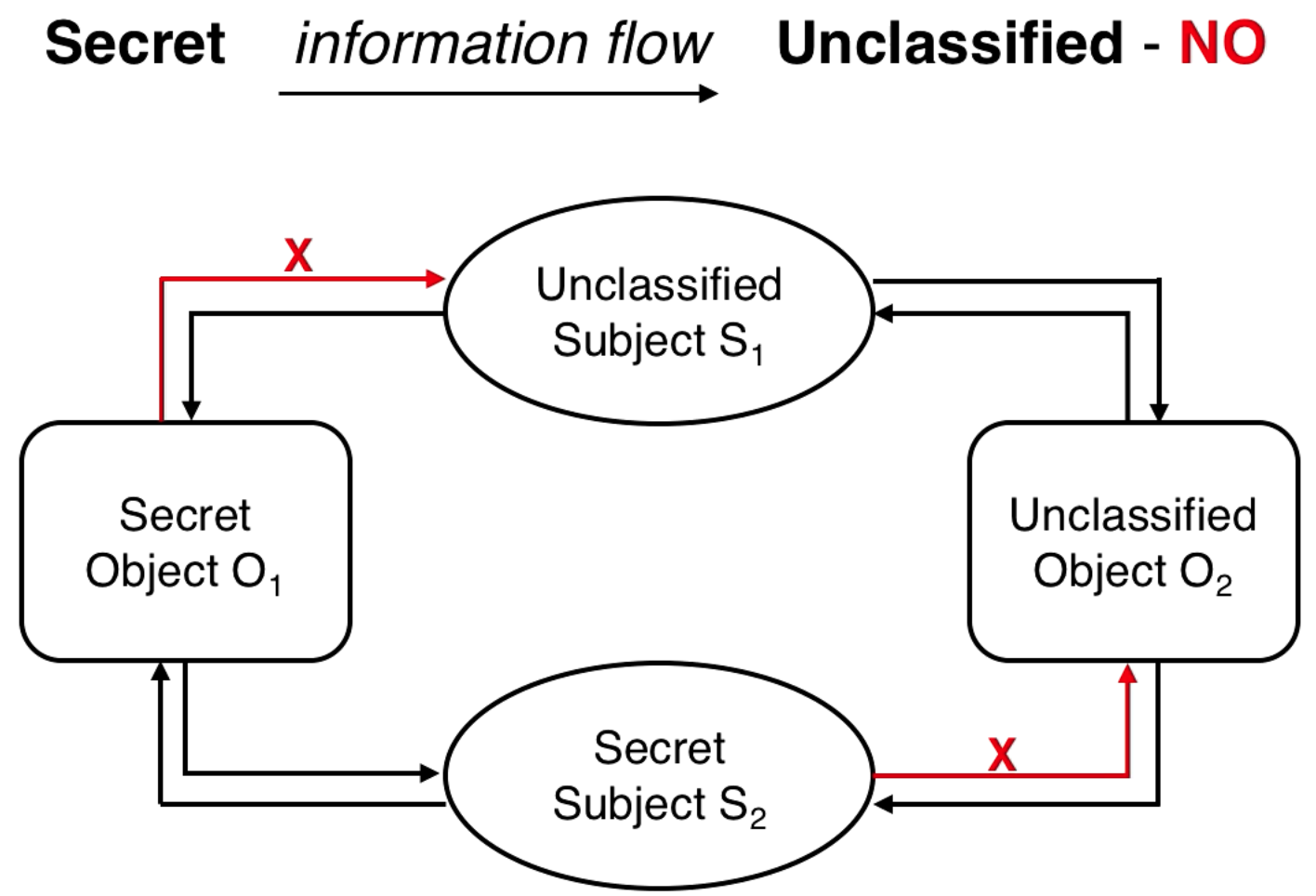
Solving Flow Control
Previously we discussed how Alice can share something with Bob who can then share it with someone who shouldn't have it. Since you can never share to a lower clearance level (write up), then this can never happen.
BLP Extras
The simple and star properties (a.k.a. read down, write up) are satisfied if and only if
- Subject
shas read permission tooimplies Label(s) dominates Label(o) - Subject
shas write permission tooimplies Label(s) is dominated by Label(o).
When is a system call allowed
The state of a system S can change. There are system calls like get_access(), release_access(), read(), write(), grant(), revoke(), etc. Calls are allowed when they follow the following rules.
-
Tranquility principle
- A subject cannot change the security class of an active object. Avoids time of check time of use vulnerabilities (TOCTOU).
-
Non-accessibility of inactive objects
- An object cannot be accessed unless activated
-
Declassification
- Lowering sensitivity level can only be done by trusted users. Trusted users don't follow the rules, they do what they want.
Biba model
The BLP model only lets you write up and read down. This is good for confidentiality but not good for integrity. The Biba model is the opposite, read up and write down. Its focus is integrity and not confidentiality.
The focus is on protecting from unauthorized modification of object.
User levels can be low, medium, or high integrity. Low integrity users cannot produce high integrity data. High integrity users do not want to read low quality data.
The purpose is to stop low quality information flowing to high level users.
Other types of flow problems
Information flow starts with sensitive data. We track reads and writes to see where the information can end up. We want to track and prevent information from exiting to places it shouldn't exit to.
BLP limitations in commercial environments
BLP works in DoD/intelligence settings where there are clearances and classifications, but most companies aren't set up this way. MAC is still important in companies because they are trying to limit how certain information gets shared.
Although there aren't clearances there are still roles. Devlopers, managers, QA, etc.
Data might be public, proprietary, related to specific projects, limited to an application (like a database), there might be conflicts of interest or a desire to separate duties (like compliance and sales departments)
The policies we examine are
- Role-based Access Control (RBAC)
- Clark-Wilson Policy
- Chinese Wall Policy
Role-Based Access Control Model (RBAC)
With RBAC a session is assigned to a user and users are assigned to roles and the roles have permissions.
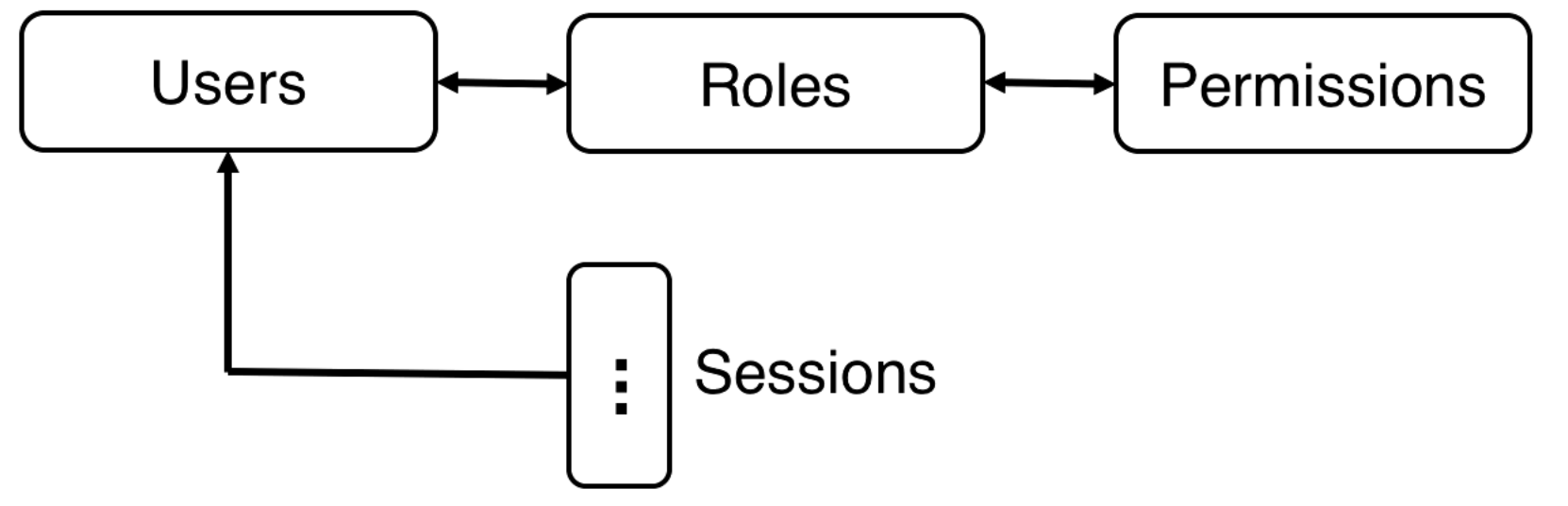
There is a policy that says what roles can be activated for a user.
RBAC formalisms
Now we define the Permission Assignment (PA) and the User role Assignment (UA).
This product is called the Cartesian product. is the set of all pairs (a, b) where .
The roles for a session are given by
The permissions
RBAC Hierarchy and Implementation
We defined RBAC0. RBAC1 allows for role hierarchies. So that a doctor is a healthcare professional and receives the permissions of a healthcare professional but may also have additional privileges. Within doctors there might be further specialization.
RBAC Implementation
There are three services
- Authentication service authenticates users.
- Role activation service allows a process running on behalf of a user to activate a requested role
- Authorization service grants access to the process on the basis of the currently active roles.
Benefits of RBAC
Roles vs. Groups
- Roles are associated with a certain job function, groups are not so explicit about this.
- Roles can be activated and deactivated, groups cannot.
- Roles have the policy file where you can find all permissions associated with them. For groups you would have to search through the ACM.
Again, roles are associated with a specific job function and groups are related users.
Small Policy File
Some notation
Without RBAC the ACM is a sparse matrix of size .
If all permissions are assigned through RBAC then we use the previously discussed Permission Assignment (PA) and the User role Assignment (UA). So the size of the policy file is the sum of the size of PA and UA. This is -
If the number of roles is relatively small, then
and the policy file is smaller than the ACM without RBAC. Small is simple, simple is better.
Clark-Wilson (CW) Policy
In many commercial settings the users are not developers that are writing code to directly interact with systems, instead they are working with applications.
In Clark-Wilson users are allowed to run certain applications. The applications the user can access depends on the job the user has. The applications have operations they can execute, these operations are called well-formed transactions.
Suppose we have four people in a company, a purchasing agent, the receiving agent, the supplier, and accounts payable. The purchasing agent buys a thing, which then sends a receipt to the receiving agent and the supplier. The order is sent from the supplier to the receiving agent. Accounts payable pays for the thing.
There is a certain order things should happen in. The receiving agent should have an order receipt before they receive the supplies. Accounts payable must receive proof of delivery before issuing the check.
Separation-of-duty
Separation of duty says that the same person should not be in charge of doing everything. In our previous example if we had the same person doing everything they could collude with the supplier to pretend as if they are buying stuff and pocket the money.
Clark-Wilson lets you have a policy that states what functions cannot be performed by the same user.
Defining CW Policy
The policy is like the ACM for Clark-Wilson. It answers -
- What users can perform what transactions, transactions not specified are not allowed for a user
- What data items can be accessed by the transactions, data not specified cannot be accessed by a transaction
- Users must perform transactions in a predefined order
In notation:
- We have constrained data items CDi. These are "constrained" because you cannot directly read/write, they are only accessible by transactions.
- We have transformation procedures (transactions) TPi
-
The policy is made up of three parts -
- Set of triples <UserID, TPi, {CDi1, CDi2, ..., CDik}>
- sequencing
- separation-of-duty (e.g., TP1 must exclude TP2)
The system is stateful, we need to be able to handle sequencing as well as separation of duty. The internal state tracks if one thing has happened before another thing so we can enfore sequencing. The system must remember who did a transaction so it can enforce separation of duty and prevent them from doing a prohibited transaction.
Implementation
We can implement parts of CW with Unix like mechanisms (ACLs, user and groups, setuid). The idea is that we give users access to execute certain programs. setuid allows the program to run with its own permissions by changing the effective uid. This way users have access to programs and programs have access to constrained data items (CDi).
Other parts of CW involving statefulness are harder to implement. The instructor encourages you to think of how to implement such things.
Chinese Wall Policy
This policy helps with conflict of interest (COI). Suppose there is a law firm with many clients, some clients may be in competition. In this case the same person should not be able to see information for both clients, it would be a conflict of interest.
- There are documents that are labeled with what company they belong to (Bank of America, Delta, Coca Cola).
- Companies for which conflict may exist are placed in the same group.
- Conflicting groups have companies with COI issues inside of them. Coca Cola competes with Pepsi for example.
The small squares inside the box for Coca Cola are documents. The box containing Coca Cola and Pepsi is a conflicting group, indicating that there is conflict of interest.
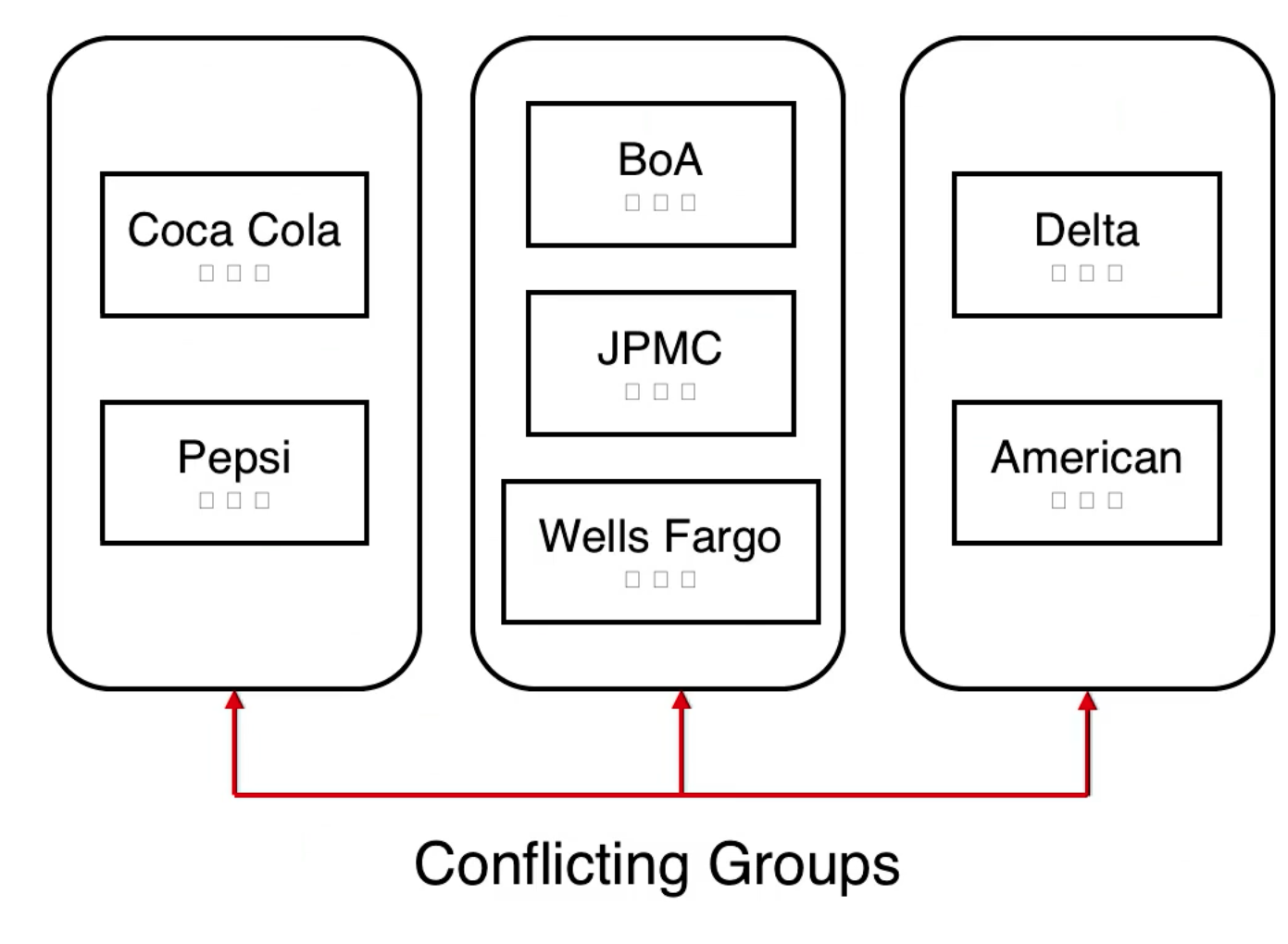
Access Rules
A user U can access an object O belonging to company C as long as U has not accessed an object from another company in C's conflicting group.
We need to implement these things by associating objects with companies and specifying conflict groups between the companies.
Policies Revisited
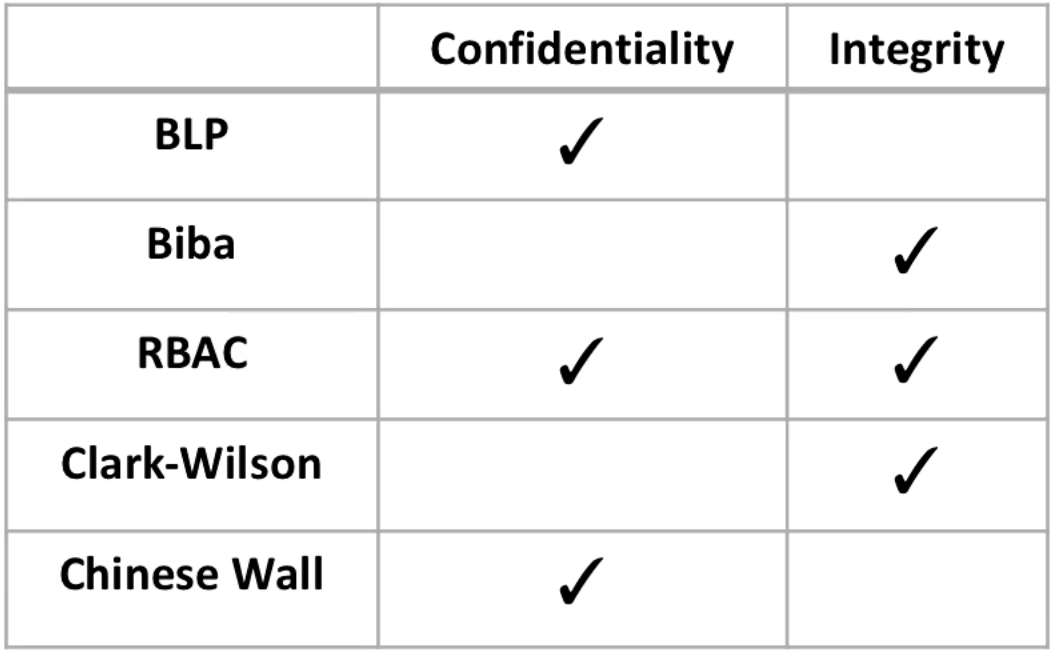
What policies address what needs?
The Bell and LaPadula (read down, write up) addresses confidentiality but doesn't address integrity. You can't read above your clearance, but you can write garbage above your clearance (bad integrity).
Biba lets you read up to higher integrity data, and write down. It addresses integrity.
If we do BLP + Biba then we get both confidentiality and integrity, but we are stuck reading and writing at one level.
RBAC enforces both read and write so it addresses both.
Clark-Wilson controls access to applications that are writing to data, it is concerned with integrity.
Chinese Wall worries about reading and disclosing data, which is confidentiality.
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy