Information Security
Operating System Security
16 minute read
Notice a tyop typo? Please submit an issue or open a PR.
Operating System Security
Operating Systems Defined
Operating systems play a really important role in computer systems. When we talk about computers, we often refer to the operating system when naming a device; for example, a Windows machine or an iOS device.
Operating systems play a critical role when it comes to protecting and securing resources present in our computer systems.
When we are looking at the arrangement of a computer system, we first start at the level of hardware. At this layer, we have the CPU, physical memory, and other I/O devices.
Direct use of hardware is really difficult. Instead of managing the hardware explicitly, we run a "program" called an operating system - such as Linux, Windows, or macOS - that handles the access and management of the low-level hardware resources.
The applications that we as users directly deal with - browsers, word processors and the like - sit on top of the operating system and interact with the physical resources through this intermediary.
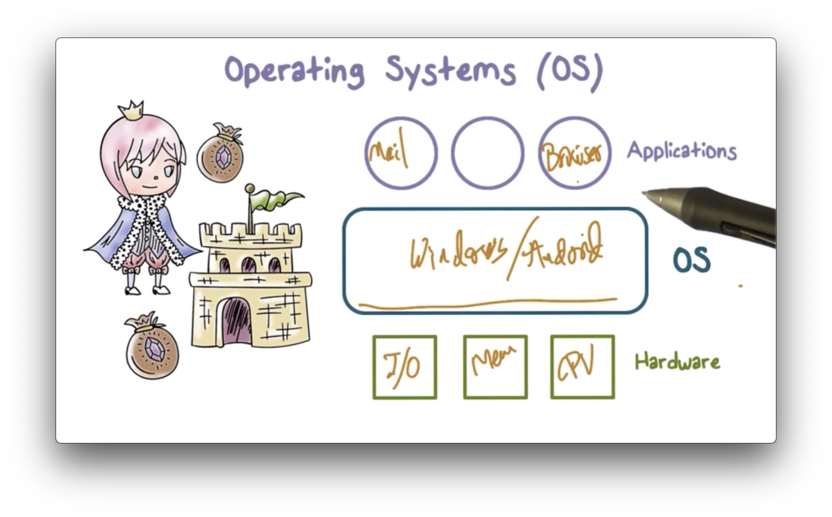
As a mediator between applications and the real, hardware resources, the operating system unsurprisingly plays an important role in the security of computer systems.
Operating Systems
Operating systems provides key functionality to the applications which rely on them.
Abstraction of hardware
The hardware is not easy to use directly. If you want to program your applications to work with hardware directly, development becomes infinitely more complex.
Thankfully, the operating system abstracts the low-level hardware APIs into simpler higher-level entities.
For example, persistent data in a computer system is stored on the disk in disk blocks. Instead of having to worry about disk management and the location/traversal of blocks, the operating system provides us with the convenient file abstraction.
These high-level abstractions allow us to interact with the underlying resources in ways that are simpler to understand and reason about, which in turn makes it easier to build applications on top of the operating system.
Controlled hardware access
The abstractions that the operating system provides to the higher applications are implemented using the real physical resources provided by the hardware.
The physical resources are shared across the application and, as a result, must be accessed in a controlled fashion.
Without controlled access, it would be all too easy for one application to overwrite data currently in use by another application. Alternatively, one application could hog the CPU and starve the other applications of execution.
Controlled access ensures that the applications across the system run cohesively.
Process Isolation
All of the different applications are running on the same system and sharing the same physical resources.
Yet, from the perspective of an individual application or process, it seems as though the process has complete and exclusive access to the entire hardware underneath.
The operating system isolates processes from one another, so each application has the feeling that it is the only one running.
Processes need not necessarily be aware of other processes.
This is important because processes may not trust each other. The operating systems isolates processes from one another while providing a trusted interface (itself) with which a process can interact with the underlying physical system.
Need for Trusting an Operating System
The operating system has direct control over basically everything in the system. It can manipulate processes running on top of it, and access hardware beneath it.
The operating system has the "keys to the kingdom", so to speak, so it is important that the operating system function as a trusted computing base (TCB) for our computer systems.
The following requirements should be met by a trusted computing base.
Complete mediation
A TCB must mediate all access to the underlying protected resources. All requests for access to hardware must pass through the operating system. Hardware use cannot circumvent the OS.
Tamper-proof
A TCB must also be tamper-proof. If untrusted code executing on top of the OS can tamper with the OS then we can no longer trust the OS.
Correctness
Finally, a trusted system is a correct system. If you are going to rely on the OS to ensure that your protected resources get used in a proper way, it is imperative that this access control is implemented correctly.
OS and Resource Protection
How does the operating system mediate requests for protected resources?
A request always has two main components:
- the entity making the request
- the target resource being requested
Identifying the entity making the request is known as authentication. Authentication establishes on whose behalf a current application or process is running.
Once we authenticate the requesting entity, we employ authorization to grant or deny access to the requested resource.
Note that the operating system doesn't autonomously decide who accesses a given resource or not. System administrators must define policies that describe who can access what, and under which circumstances.
The operating system implements a policy by performing access checks and either granting or denying access in accordance with the policy.
Secure OS Quiz 1

Secure OS Quiz 1 Solution

Secure OS Quiz 2

Secure OS Quiz 2 Solution

A system call requires control transfer from the calling process into the OS, which then must perform authentication/authorization checks before granting access and transferring control back.
This is more costly than a regular call, which incurs none of this overhead.
Secure OS Quiz 3

Secure OS Quiz 3 Solution

Processes run on behalf of users. Users must login to the system to run applications/processes.
How Can We Trust an OS?
How is an operating system tamper-proof? In other words, how does an operating system maintain its isolation and integrity despite untrustworthy applications and users executing on top of it?
The operating system needs help from the hardware. Particularly, the hardware needs to protect the memory where the operating system resides, and block unprivileged attempts from interacting with memory at those locations.
The CPU executes in different execution modes (also known as execution rings), which serve as execution environments with varying privileges. The most privileged ring is ring 0, and privileges are revoked as you move up to higher rings.
Many architectures support more than two (user and system) execution rings.
Thanks to these rings, the processor is aware of which kind of code it is executing - be it untrusted user code or trusted system code - and knows that it shouldn't access code or data belonging to a higher privilege level.
Certain privileged hardware instructions can only be executed when the processor is executing in ring 0. These instructions are usually ones that provide direct access to the hardware: manipulating memory, interacting with devices, and so forth.
System Calls From User to OS Code
System calls are used to transfer control between user and system code.
These calls cannot be arbitrary. The operating system exposes an API which enumerates the specific ways in which applications can interact with it. For example, here are the system calls for Linux.
These calls must enter the operating system in a controlled fashion. They come through call gates, which are accompanied by a processor privilege ring change on system entry and exit.
Crossing this boundary means that the operating system will have to change some data structures that keep track of memory mappings, because we will be able to access memory now that we couldn't access before. In addition, certain registers will have to be saved, while others have to be loaded.
This used to happen via a hardware interrupt/trap into the system from user mode, but in x86 architectures, we have explicit instructions to cross the system boundary: sysenter to enter the operating system during the system call and sysexit to return from the system call.
The extra work of adjusting privilege rings, changing memory mappings, and loading/saving additional registers makes these calls more costly.
Untrusted User Code Isolation
Untrusted user code has to be isolated from the system code. How can we achieve this isolation?
All the processor does is fetch the next instruction and execute it. Some of these instructions may be read/write or load/store requests. If the processor receives one of these requests supplied with a memory address belonging to the operating system, what stops it from executing that instruction?
We can rely on the hardware to protect memory. If you are running in user mode, the hardware will block an attempt to generate an address and complete a read or write in a memory location that belongs to the operating system.
This hardware protection also applies to processes trying to access memory belonging to other processes. The hardware enforces that processes only access memory that has been made available to it, blocking access to any other memory locations.
User Isolation Quiz

User Isolation Quiz Solution

Address Space
From a process's point of view, it has the entire computer to itself. It isn't aware that it shares physical memory with other processes.
This is made possible by the address space abstraction that the operating system creates for a process upon creating the process itself.
An address space contains a sequence of contiguous memory locations (from zero to some max) that a process can address and utilize for its own data and instructions.
The address space serves as the unit of isolation between processes sharing the same physical hardware resources.
The memory that a process views may be larger than the actual physical memory present on the system, a feat made possible by virtual memory.
The address space usually contains 2^32 addresses (for a 32-bit architecture) or 2^64 addresses (for a 64-bit architecture).
Unit of Isolation
Physical addresses point to locations in physical memory, but addresses in an address space don't directly reference physical locations. Instead, these logical addresses must be translated into physical addresses by the operating system.
For example, the operating system might maintain a map that connects logical address 2000 in process A's address space to to physical address 5000.
When process A is running, its address space maps to certain physical addresses in memory. When process B is running, its address space maps to different physical address in memory.
Even though the physical addresses corresponding to the address spaces of two processes are often interspersed, each process views its address space as contiguous and exclusive.
Address Translation
The reason that translation has to happen is that the address space that the process is provided is just an abstraction of the physical memory layout underneath.
For example, the process thinks it has access to a chunk of contiguous memory - which it doesn't - and in some cases the process may think that it has access to more memory than is currently physically available.
Naturally, the operating system needs to maintain a system to map between the abstraction and the reality.
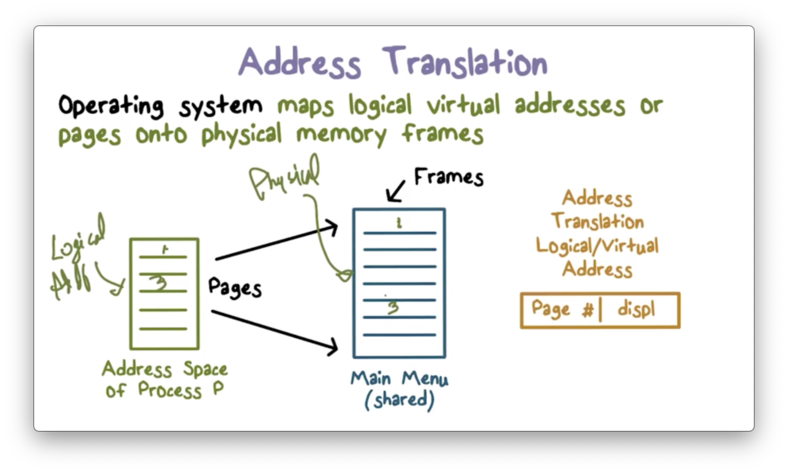
This mapping process does not occur byte for byte. The number of mappings we would have to maintain if this were the case would not be scalable.
Instead, we divide the address space into larger chunks, called pages. A common page size is 4kb.
Thus, we can think about the representing any address within the address space as a page number and an offset within that page.
A page table maintains the mapping between logical pages and physical pages. The operating system is responsible for building, maintaining, and protecting these tables.
When a process needs to retrieve data from an address in its address space, the operating system must first map that logical page to the correct physical page and carry the offset.
For example, the page table might have an entry that maps logical page 3 to physical page 8. This means that if a process is requesting some byte at offset d from the start of page 3, the operating system will fetch the byte at offset d from the start of physical page 8.
By using pages, we can reduce the number of entries in our lookup table from the number of addresses in the address space to that number divided by the page size.
For example, with 4kb pages and 32-bit addresses, we can reduce the number of entries in the page table from 2^32 to 2^20 (2^32 / 2^12)
Virtual address translation - as maintained by page tables - ensures that a process can only access physical memory for which a corresponding logical address mapping exists in its page table.
Code Protection
The operating system will not map a virtual page of process A to a physical page that has been given to process B, unless the two processes wish to share memory.
Put another way: two page tables, each for a different process, will not contain a mapping to the same physical page at the same time.
What this means is that it is impossible for process A to access physical memory belonging process B, because process A has no way to address that memory.
Process Protection through Memory Management
Protecting processes from each other and protecting the operating system from untrusted process code follow the same mechanism.
Page table lookups prevent a process from accessing any physical pages that belong to the operating system, since the operating system has not explicitly mapped those locations into the process's address space.
This translation process is so important that we typically have a piece of hardware called a memory management unit (MMU), that helps the OS perform this translation efficiently, using memory caches such as translation look-aside buffers.
In addition to resolving a physical address from a virtual address, a page table entry can provide information about different types of memory access available for that page.
For example, an entry may store some information as to whether a given page is available for reading, writing, execution, or some combination of the three. These RWX bits can limit the type of access that a process can perform on addressable memory.
As a result, interacting with memory really has two components: first, understanding which memory locations are even available to a process, and; second, understanding which types of accesses are permitted on those locations.
Revisiting Stack Overflow Quiz

Revisiting Stack Overflow Quiz Solution

Preventing Malicious Code Execution
One of the strategies that we have talked about for protecting against a stack buffer overflow attack is to use a non-executable stack.
While a malicious user might still be able to inject malicious instructions onto the stack, those instructions will not actually be executed.
The operating system can achieve this by not writing an executable bit for any page table entry associated with the virtual addresses within the process's stack.
Windows, OS X and Linux all make the stack non-executable.
OS Isolation from Application Code Part 1
Protecting processes from each other and protecting the operating system from untrusted process code follow the same mechanism.
The operating system (kernel) resides in a portion of each process's address space.
The address space in which a process executes now has two sections: the user code/data and the kernel code/data. This partitioning exists for every process that we have in the system.
Whenever a process wants to access a portion of the address space that contains kernel data or code, the process must make a system call to traverse that boundary.
Page tables, protection bits, and execution rings all play a role in establishing and enforcing this segregation within the address space.
OS Isolation from Application Code Part 2
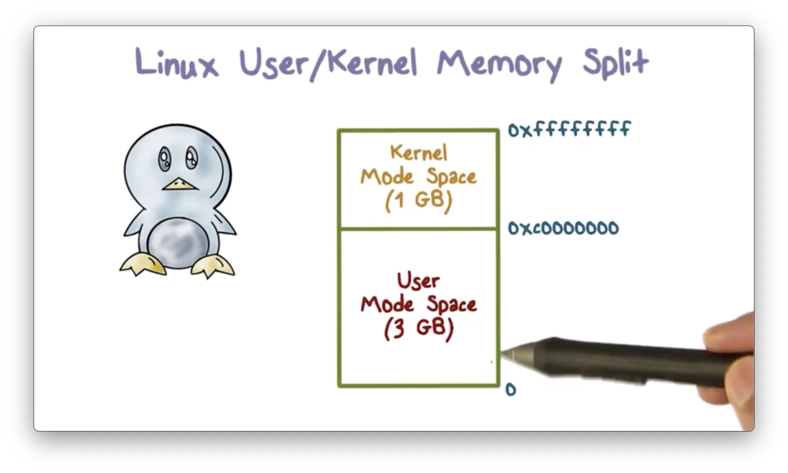
For 32-bit Linux systems, the address space is 4GB. Of that 4GB, the lower 3GB is used for user code/data, and the top 1GB is used for the kernel.
Access to different portions of address space (user vs kernel) are governed the current privilege ring in which a process is currently executing.
In x86 systems, a process must be in ring 0 to access kernel code. If it is operating in user mode (ring 3), it can't access the kernel portion of the address space.
The 1GB points to the same kernel code in each process (i.e. we aren't copying code for each process that is created), but the 3GB section is unique for each process.
While modern operating systems create this fence between untrusted code and trusted code, older operating systems didn't do this.
For example, MS-DOS does not have this separation. This means that any process could alter operating system code. Clearly, this is a vulnerability of this early OS.
Kernel Memory Split
Execution Privilege Level Quiz

Execution Privilege Level Quiz Solution

Complete Mediation: The TCB
The second requirement of the a TCB is complete mediation.
Complete mediation means that the TCB must be aware of any and all accesses to resources it protects.
How do we implement complete mediation in operating systems?
We have to make sure that no protected resource - for example, a memory page or a file - can be accessed without going through the kernel.
We can achieve this by making the kernel act as a reference monitor that cannot be bypassed. This means that all references to underlying resources must be resolved by the operating systems in order to be valid.
We just saw an example of this with address spaces. A process can only access memory once the operating system translates its virtual reference into a real, physical memory location.
Complete Mediation: The User Code
Protected resources are implemented by the operating system, and the data structures that are utilized to access those resources - page tables, for example - live in the kernel portion of the address space.
While a process is executing user code, it can't access that portion of your address space. The process will need to switch to the system mode through a system call, and this transfer of control will be mediated by the operating system itself.
In addition, user code cannot access physical resources directly because interacting with those resources often requires access to privileged instructions that can only be executed in system mode.
Complete Mediation: OS
At user level, a process has access to virtual resources and the operating system exposes APIs for how those virtualized resources can be used.
For example, a process doesn't access a disk block directly. Instead, the operating system performs the disk I/O, and abstracts the disk controller operations into the file interface, which a process can use to read from and write to files.
Since virtual resources are just abstractions of physical resources, there must be a translation process whereby the virtual reference resolves into a physical reference.
If you want to access a disk block or a page of memory for example, you have to start with a file descriptor or a virtual address, and let the OS map these references into the appropriate physical resources.
This level of indirection added by the operating system makes it impossible for a process to directly reference physical resources and allows the OS achieve complete mediation.
Virtualization
We don't have to stop at virtualizing individual physical resources. The concept of translating virtual resources into physical resources can apply to the computer system as a whole, giving rise to virtual machines.
Virtual machines provide functionality needed to execute entire operating systems, and an intermediary known as a hypervisor manages the hardware on behalf of one (or more!) operating systems running on top of it.
The main motivation for virtualization comes from the fact that operating systems are large and complex, and different applications may require different underlying operating systems.
One use of virtualization commercially is to free users from being limited to using one operating system and be able to use multiple operating systems on the same physical system.
Limiting the Damage of a Hacked OS
Remember that if an operating system is compromised, all applications running on that system will be compromised because they all share and trust the OS.
Virtualization can help limit the damage caused by a compromised/hacked operating system.
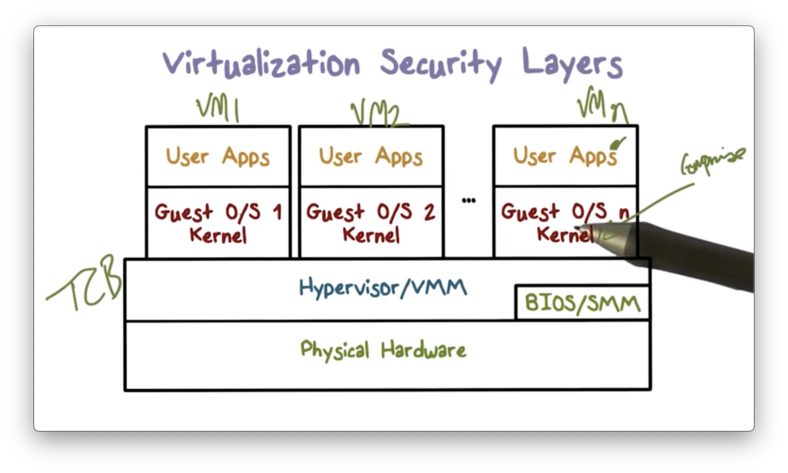
In virtualized systems, we introduce a hypervisor between the hardware and the operating systems. On top of the hypervisor, we support virtual machines, which have their own operating system - called the guest operating system - which itself can support a number of applications.
Compromise of an OS within one virtual machine only impacts the applications running inside of that virtual machine. The applications that are running in an adjacent virtual machine atop the same hypervisor are unaffected.
With virtualization we can achieve isolation between virtual machines - each with their operating system - where earlier we only had isolation between processes.
In this case, the TCB is now the hypervisor, which manages the hardware resources on behalf of the virtual machines.
Virtualization Security Layers
Correctness: The Final TCB Requirement
Correctness is important because compromise of the OS means that an attacker has access to all the physical resources: every memory page, every block on disc, etc.
Meeting the correctness requirement for operating systems is really hard. Operating systems are very complex, and we've already discussed how added complexity can make security much more difficult.
Virtualization can help with correctness by reducing complexity. The hypervisor can be much smaller and simpler than the operating system since all it has to do is partition physical resources among virtual machines.
TCB Requirements Quiz

TCB Requirements Quiz Solution

In this case, we have tampered with the TCB by turning off the check. The access still proceeds through the operating system, and is still technically correct (i.e. the access wasn't permitted because of a bug).
Size of Security Code

Size of Security Code Solution

I think the point being made here is that the increase in complexity may be accompanied by an increase in vulnerability.
Hypervisor Code Size Quiz

Hypervisor Code Size Quiz Solution

Again, the argument being made here is that using a hypervisor as a TCB, with fewer lines of code than a full-fledged operating system, might be a more secure choice.
OMSCS Notes is made with in NYC by Matt Schlenker.
Copyright © 2019-2023. All rights reserved.
privacy policy